 About
About 


The 1992 release of Superman #75, the Death of Superman issue, stands out as a unique moment in comics history. The original art is now up for auction.
Posted in: Comics | Tagged: anne hathaway, Comics, dc comics, guardians of the galaxy, hawkeye, iron man, marvel, microsoft, scarlet witch
Microsoft AI Strikes Again: Anne Hathaway As A Woman In A Black Suit Case, And Other Classification Misadventures
Oh, Microsoft. First there was Tay the Twitter bot, and now this. Not that there's much similarity between Tay and the Microsoft Computer Vision API, except that at least for now… where there's AI, there are humans who will abuse it. I'm starting to get the feeling that might not turn out so well for us in the end, but never mind that now.
Doing a little dev work for the site recently, I was preparing to put together a new section and realized it'd be useful to be able to tag lots of images quickly and automatically, and decided to check out the state of the art in that area. Read some good things about Microsoft's Computer Vision API, and decided to put it to the test:
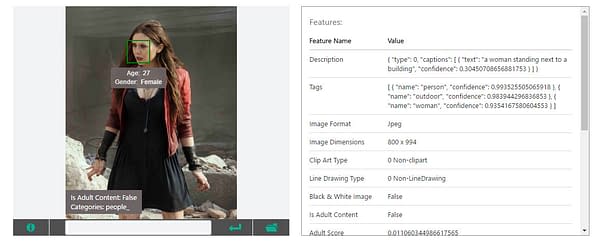
In the case of movie stills, Vision API is more or less in familiar territory, it seems. "A woman standing next to a building" is essentially correct here, and the age estimate of 27 is right on the money for Elizabeth Olsen, as a matter of fact.
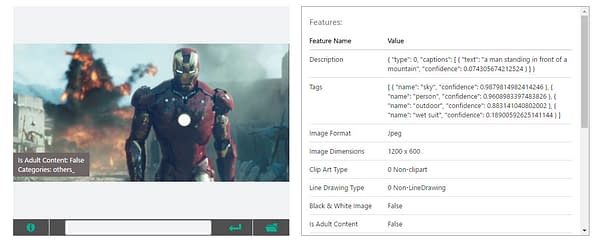
"A man standing in front of a mountain" is not correct for this Iron Man scene, but you can see why the Vision API might think that. (there's probably a good joke to be had about Ultron here, but I'll leave it to your own imagination, or the comment section)
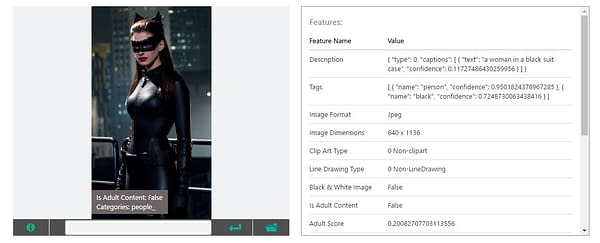
So, not flawless but not awful on those. But then there's this pic of Anne Hathaway as Catwoman. Vision API doesn't understand what it's seeing with the catsuit, and thus makes a guess that this pic is "A woman in a black suit case"
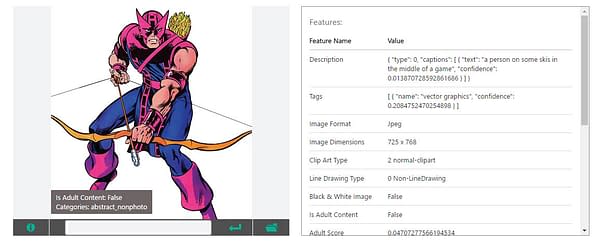
An odd description to say the least, but it's nothing compared to what Vision API thinks of comic book art:
Hawkeye is "A person on some skis in the middle of a game"
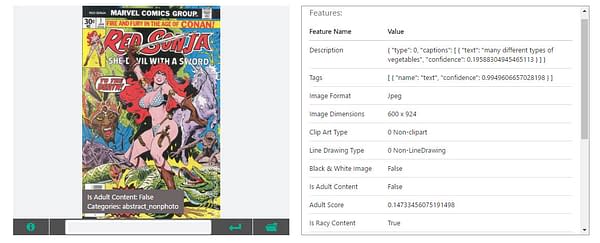
Red Sonja is "Many different types of vegetables" One wonders if Tay was a bad influence on its distant cousin the Vision API on this one. This is also one of the few images I tested that Vision API classified as "racy content", though holding that opinion while also thinking that this is a depiction of vegetables makes one wonder what androids do (deep)dream of, if it isn't electric sheep.
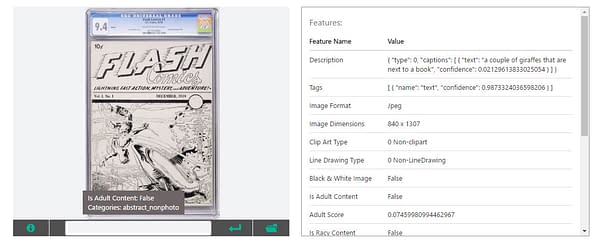
The CGC 9.4 copy of the Flash Comics #1 ashcan is "A couple of giraffes that are next to a book". Very bizarre, and it's hard to see how Vision API came up with a couple of giraffes here. But in fairness to Vision API, I should note that I'm cherry picking my results for this post, as many of the ones not shown are less interesting variations on the description "A picture of a book". This was particularly true of comic scans or photos for which the edges of the comic were apparent within the image. As I was testing, I eventually realized it was picking up on that and in some cases interpreting title logos & trade dress as something associated with books. Of course, "A picture of a book" is more or less correct in many of these cases.
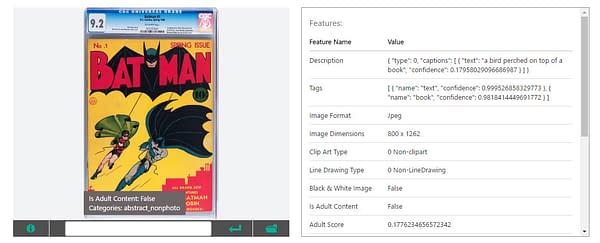
The CGC 9.2 copy of Batman #1 is "A bird perched on top of a book". Not so far off, looked at a certain way.
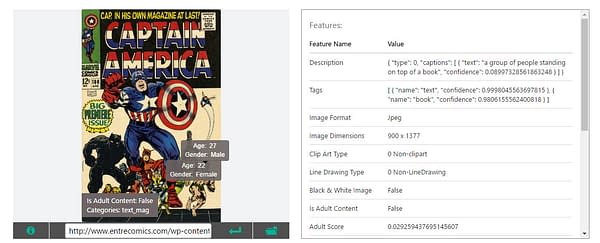
Captain America #100 is "A group of people standing on top of a book". I love this one, the interpretation being that Kirby's composition is so effective that the characters are standing on top of the comic rather than in it. The classification of Thor as a 22 year old female is likewise interesting.
About the rest of these… I just don't know. Brave and Bold #28 is "A picture of a bicycle"
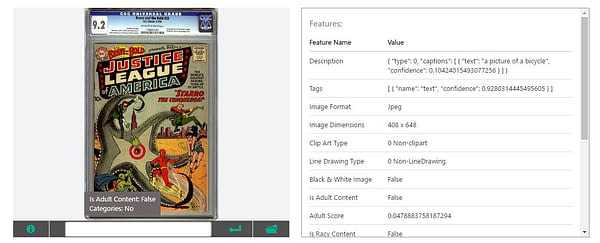
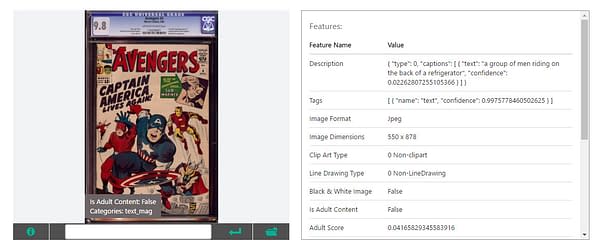
Avengers #4 is "A group of men riding on the back of a refrigerator"
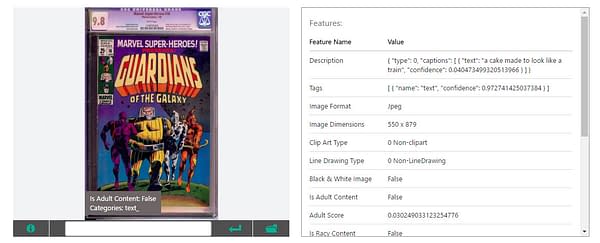
Marvel Super-Heroes #18 is "A cake made to look like a train"
It didn't take too much more testing than this for me to conclude that Vision API isn't currently suitable for my use case. All kidding aside, I still appreciate the effort from Microsoft, and expect this API to improve quickly. Sorry Vision API, but I'll check in again in a few months, and in the meantime hope that if you improve and evolve and end up guiding any motor vehicles or other heavy equipment in my area someday soon, that you also will have learned how to take a joke.
Enjoyed this? Please share on social media!
Stay up-to-date and support the site by following Bleeding Cool on Google News today!










